
 云计算实验二手册
云计算实验二手册
云计算实验二手册,主要包括四个部分,Hadoop的安装、Hadoop的配置、WordCount、和KMeans,如果有发现什么问题可以私戳我或者在评论区提出。
# 一、Hadoop本体安装
由于第一次实验使用了Ubuntu22.04,为了方便我们这次实验使用的操作系统也是Ubuntu22.04。
# 1. 安装java
Hadoop 基础组件及其外围项目大多是基于 Java 的,要运行 Hadoop,我们需要在系统中安装 Java 运行时环境(JRE)。有多种 JRE 可供选择,我们使用 openjdk-11 作为 JRE。Hadoop 官方文档中说明了对 Java 版本的支持情况。Hadoop 框架使用 SSH 协议与本地(或远程计算机)进行通信,我们需要在本地计算机中安装 SSH 服务器守护程序。
sudo apt install openjdk-11-jdk openssh-server -y
# 2. 创建ssh密钥并添加到自己的本地计算机
Hadoop 通常运行于分布式环境中。在这种环境下,它使用 SSH 协议与自己(或其他服务器)进行通信,为了能够配置 Hadoop 更安全地与服务器进行通信,我们为本地环境 hadoop 用户生成公-私密钥对,以支持 SSH 中的密钥对认证:
ssh-keygen -b 4096 -C "for hadoop use" # 为了方便这里可以直接一路回车,如果有需要可以自己按照提示修改
ssh-copy-id -p 22 localhost
2
上述命令生成带备注信息的长度为 4096 位的 RSA 密钥,并将密钥复制至本地计算机中,用于支持 SSH 密钥对认证方式。
这时候可以尝试使用ssh localhost,应该可以无密码登录。
# 3. 下载并解压hadoop
Hadoop 的各种发行版本通常从 Hadoop 官方网站的下载页面 (opens new window)下载。
我们使用来自 Hadoop 官方网站的发行版本 3.3.6 举例。我们准备将相关发行版本安装至文件系统的 /opt 目录下。
首先从下载页面获得 Hadoop 的发行版文件:
wget "https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz"
如果以上官方链接无法访问或者速度较慢,可以使用以下命令替代:
wget "https://mirrors.bit.edu.cn/apache/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz"
注意该压缩包较大(696MB),因此下载需要的时间可能较长。
下载好压缩包后,解压到/opt目录。
sudo tar -zxvf hadoop-3.3.6.tar.gz -C /opt
# 二、Hadoop 配置
Hadoop 并非是单个软件,而是一系列大数据存储及处理的工具集合。所以,有必要针对常用的基础组件进行配置,以完成 Hadoop 环境的搭建。
# 1. 配置环境变量
安装 Hadoop 后,我们需要正确设置以下环境变量。可以将这些添加环境变量的命令添加至 ~/.bashrc 文件末尾,以避免每次登录时都需要执行,注意以下命令需要一次性复制和运行,不可以分多次:
注意
注意以下命令需要一次复制,不可分多次
cat << 'EOF' >> ~/.bashrc
export HADOOP_HOME=/opt/hadoop-3.3.6
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
EOF
2
3
4
5
6
7
8
9
10
11
然后执行source ~/.bashrc使配置生效或者直接重启shell。
# 2. 配置Hadoop基础框架
顺利运行 Hadoop 组件,我们有必要告诉 Hadoop 有关 Java 运行时环境(JRE)的位置信息。Hadoop 框架的基础配置文件位于 ./etc/hadoop/hadoop-env.sh 中,我们只需要修改其中的 JAVA_HOME 行。如果你使用其他方式(比如非标准端口)通过 SSH 客户端连接到(本地)服务器,则需要额外修改 HADOOP_SSH_OPTS 行。
首先我们接下来的操作都需要以/opt/hadoop-3.3.6作为当前路径,也就是说你需要先cd到/opt/hadoop-3.3.6,另外注意以下命令同样需要一次性复制和运行。
注意
注意下文中很多路径是./etc/hadoop/hadoop-env.sh,是一个相对于/opt/hadoop-3.3.6的相对路径,不是系统中的/etc
另外注意以下命令同样需要一次复制,不可分多次
cat << 'EOF' >> ./etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_SSH_OPTS="-p 22"
EOF
2
3
4
注意
根据系统架构不同,Java 可执行文件的位置或名称是略有不同的。
如果不是/usr/lib/jvm/java-11-openjdk-amd64,可能需要根据实际修改。
# 3. 核心变量配置
Hadoop 生态的大多数组件采用 .xml (opens new window)文件的方式进行配置,linux的作者Linus Torvalds也曾对xml发出过“友好”的评价 (opens new window)。它们采用了统一的格式:即将配置项填写在每个配置文件的 <configuration> 与 </configuration> 之间,每个配置项通过以下的方式呈现:
<property>
<name>配置项名称</name>
<value>配置值</value>
</property>
2
3
4
首先需要修改./etc/hadoop/core-site.xml,我们需要配置fs.defaultFS为hdfs://localhost/,也就是说,需要把以下内容添加到./etc/hadoop/core-site.xml的<configuration> </configuration>之间。
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost/</value>
</property>
2
3
4
# 4. 配置 HDFS(Hadoop 文件系统)
为了支持Hadoop的运行,我们需要使用能支持分布式的文件系统,HDFS就是为了Hadoop使用的,你可以从这里 (opens new window)找到HDFS的更多信息。
在使用 Hadoop 文件系统(HDFS)之前,我们需要显式配置 HDFS,以指定 NameNode 与 DataNode 的存储位置。我们计划将 NameNode 与 DataNode 存储于本地文件系统上,即存放于 ~/hdfs 中:
mkdir -p ~/hdfs/namenode ~/hdfs/datanode
然后,修改./etc/hadoop/hdfs-site.xml,将以下内容放到该文件的<configuration> </configuration>之间。请注意需要替换其中的liyaning为你的ubuntu用户名
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/liyaning/hadoop/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/liyaning/hadoop/datanode</value>
</property>
2
3
4
5
6
7
8
9
10
11
12
13
14
首次启动 Hadoop 环境之前,我们需要初始化 Namenode 节点数据,使用以下命令:
hdfs namenode -format
应该可以看到很多输出信息。
# 5. 配置 MapReduce(由 YARN 驱动)
MapReduce 是一种简单的用于数据处理的编程模型,YARN(Yet Another Resource Negotiator)是 Hadoop 的集群资源管理系统。
将以下内容放到./etc/hadoop/mapred-site.xml的<configuration> </configuration>之间。
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.3.6/</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.3.6/</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.3.6/</value>
</property>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
将以下内容放到./etc/hadoop/yarn-site.xml的<configuration> </configuration>之间。
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
2
3
4
5
6
7
8
# 6. 启动Hadoop集群
使用以下命令:
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
2
3
可能会出现ssh的提示Are you sure you want to continue connecting (yes/no/[fingerprint])?,直接yes就可以。
这将启动以下守护进程:一个 namenode、一个辅助 namenode、一个 datanode(HDFS)、一个资源管理器、一个节点管理器(YARN)以及一个历史服务器(MapReduce)。为验证 Hadoop 相关服务启动成功,可以使用jps命令。
你可以使用浏览器访问该主机的 9870 端口,以查看 HFS 的相关情况,如果一切正常,应该能在浏览器看到以下类似画面。
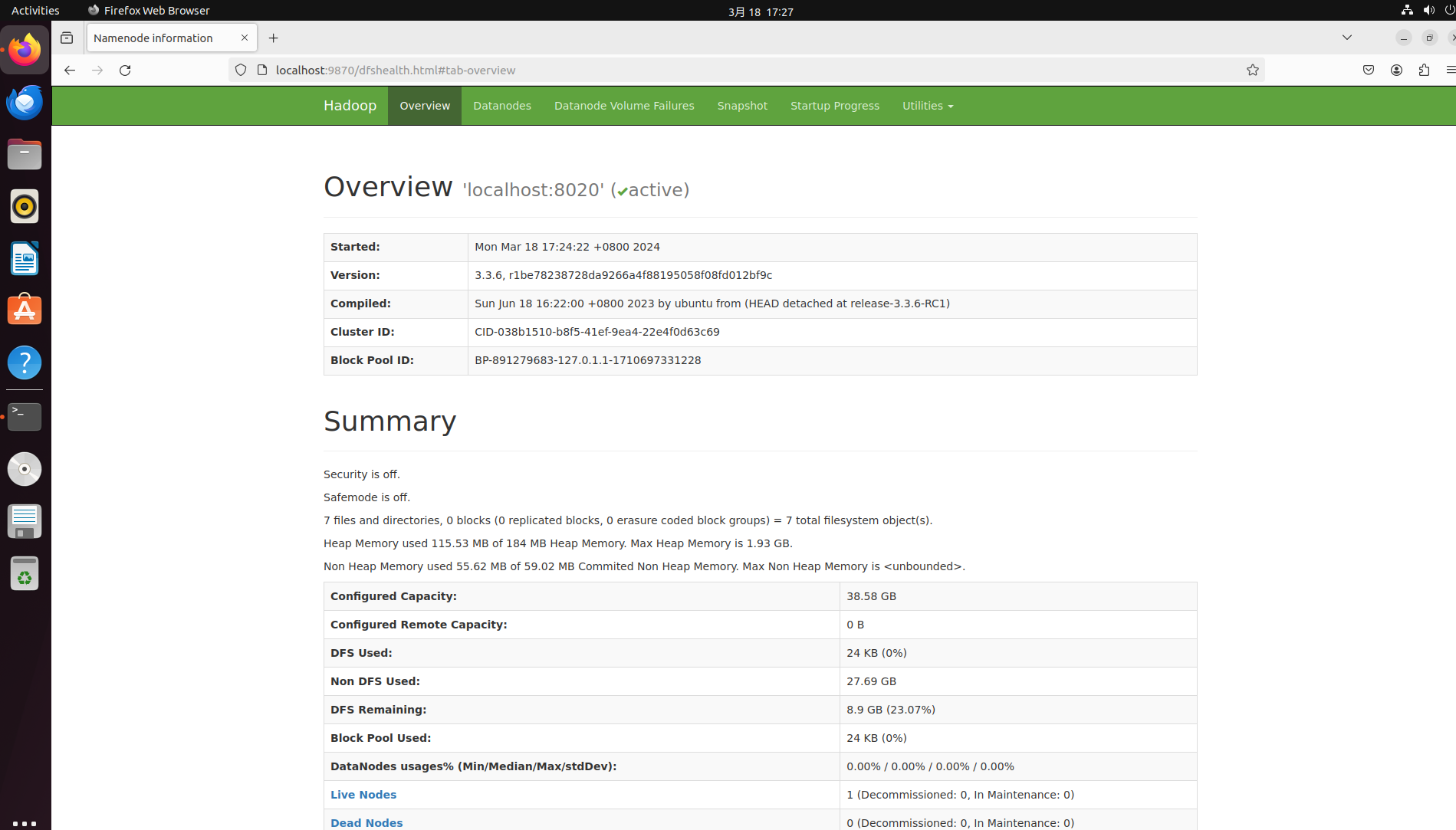
大功告成!此时hadoop基础的组件已经安装完成。如果你发现某些组件未按预期工作,你可以在 Hadoop 安装目录的 ./logs 下找到各服务对应的运行日志进行排查。
# 三、WordCount实验
# 1.安装maven (opens new window)
首先使用命令sudo apt-get install maven。
将配置文件复制到~/.m2目录:mkdir ~/.m2 && cp /etc/maven/settings.xml ~/.m2。
编辑~/.m2/settings.xml文件,将以下内容添加到<mirrors></mirrors>中间。
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>https://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
2
3
4
5
6
# 2. 创建项目
使用以下命令,这将在当前文件夹创建一个workcount文件夹,请选择一个合适的路径来创建项目,注意替换其中的liyaning为你的姓名
mvn archetype:generate -DarchetypeGroupId=org.apache.maven.archetypes -DgroupId=cn.edu.seu.liyaning -DartifactId=wordcount -DpackageName=cn.edu.seu.liyaning -Dversion=1.0-SNAPSHOT -DinteractiveMode=false
# 3. 编辑pom.xml
进入workcount文件夹,下面的操作可以直接使用vim或者gedit这样简单的文本编辑器,或者为了方便也可以使用VSCode之类的文本编辑器或者IDEA之类的Java IDE。
编辑pom.xml,在<dependencies></dependencies>之间添添加如下内容:
点击查看
<dependency>
<groupId>commons-cli</groupId>
<artifactId>commons-cli</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.8.5</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.5</version>
<scope>provided</scope>
</dependency>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
在</dependencies>后面增加如下内容:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
2
3
4
5
6
7
8
9
10
11
12
使用mvn clean install -DskipTests同步依赖,或者直接使用IDE。
新建src/main/java/cn/edu/seu/{你的姓名}/WordCount.java
内容如下,就是给出的word文档里面的原文没有修改,注意替换第一行的包名:
点击查看
package cn.edu.seu.liyaning;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
然后使用命令mvn clean install -DskipTests打包,应该可以看到当前目录的target文件夹下多了一个wordcount-1.0-SNAPSHOT.jar文件。
# 4. 在HDFS中创建一个文本文件
hdfs dfs -mkdir /miao # 创建文件夹
hdfs dfs -ls / # 应该可以看到miao这个文件夹
2
3
在本地创建一个miao.txt,随便写一些内容,原版实验手册中给出的文本内容如下:
Long long ago, there is one cat that is expected at using the cat utility on Linux. One day, it saw a spring in the spring in spring. He is astonished and laughing to death.
Years later, people mark the 9 May as the Dying Cat Linux Day to celebrate the people who is struggling at using Linux.
Written by a people who loves cat.
Please add your own student id and name here:
1845** Zhang Shan
2
3
4
5
6
7
8
然后把这个文件放到hdfs中去:
hdfs dfs -put miao.txt /miao/
hdfs dfs -ls /miao # 应该可以看到miao.txt
2
# 5. 使用Hadoop运行编译的jar文件
注意替换其中的文件真实路径以及包名:
hadoop jar ~/wordcount/target/wordcount-1.0-SNAPSHOT.jar cn.edu.seu.liyaning.WordCount /miao/miao.txt /miao/output/
等待大概1分钟之后运行完毕,使用hdfs dfs -ls /miao/output命令可以看到有一个_SUCCESS文件和一个part-r-00000文件。
使用hdfs dfs -cat /miao/output/part-r-00000可以看到运行的结果。
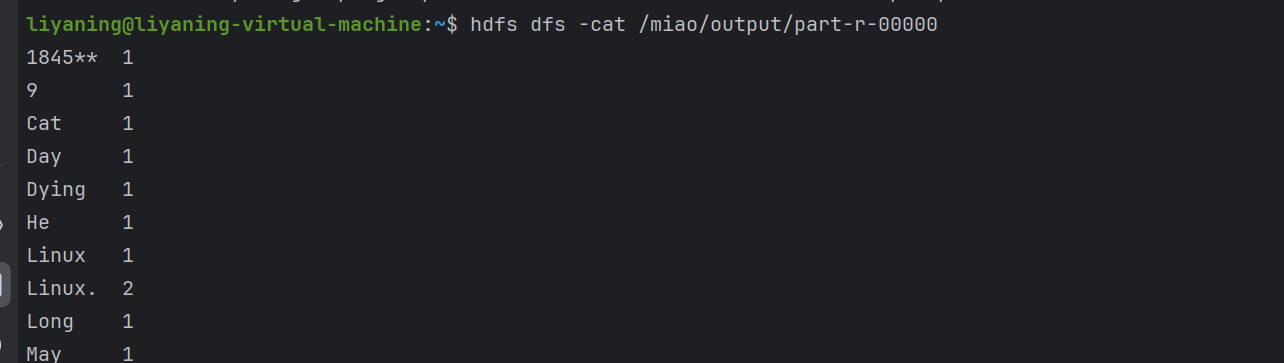
Bingo!第一个小实验完成。
# 四、KMeans实验
# 1. 准备相关文件
首先解压KMeans.zip。
unzip KMeans.zip
cd KMeans/
2
使用java -jar ProcessCorpus.jar将文本文件转化成词向量,该程序会要求你输入一些信息,可以按照以下内容输入:
Enter the directory where the corpus is located: 20_newsgroups
Enter the name of the file to write the result to: vectors
Enter the max number of docs to use in each subdirectory: 100
How many of those words do you want to use to process the docs? 10000
使用java -jar GetCentroids.jar初始化集群起始点,该程序会要求你输入一些信息,可以按照以下内容输入:
Enter the data file to select the clusters from: vectors
Enter the name of the file to write the result to: clusters
Enter the number of clusters to select: 20
然后把刚刚创建的文件复制到HDFS中:
hdfs dfs -mkdir /data
hdfs dfs -mkdir /clusters
hdfs dfs -copyFromLocal vectors /data
hdfs dfs -copyFromLocal clusters /clusters
2
3
4
# 2. 构建项目
首先使用如下命令创建项目,请注意需要替换其中的liyaning为你的ubuntu用户名。
mvn archetype:generate -DarchetypeGroupId=org.apache.maven.archetypes -DgroupId=cn.edu.seu.liyaning -DartifactId=kmeans -DpackageName=cn.edu.seu.liyaning -Dversion=1.0-SNAPSHOT -DinteractiveMode=false
然后编辑pom.xml,操作方法同wordcount中的pom.xml。
再然后,把KMeans文件夹中,MapRedKMeans下的所有文件复制到src/main/java/cn/edu/seu/XXX/,可能根据需要修改以下命令:
cp ../MapRedKMeans/* src/main/java/cn/edu/seu/liyaning/
然后使用mvn clean install -DskipTests构建项目,应该可以看到当前目录的target文件夹下多了一个kmeans-1.0-SNAPSHOT.jar文件。
# 3. 运行项目
使用命令提交到Hadoop运行:
hadoop jar target/kmeans-1.0-SNAPSHOT.jar KMeans /data /clusters 3
其中3是kmeans的迭代次数,可以自己定义,当然次数越多需要的时间可能也越久。
执行完毕后,使用命令将结果从HDFS拷贝回本地,注意需要先cd到解压出来的KMeans文件夹,方便后续检查结果:
cd KMeans # 根据实际替换为你的解压出来的文件夹路径
hdfs dfs -copyToLocal /clustersXXX/part-r-00000 # 替换XXX为你的迭代次数
2
# 4. 检查结果
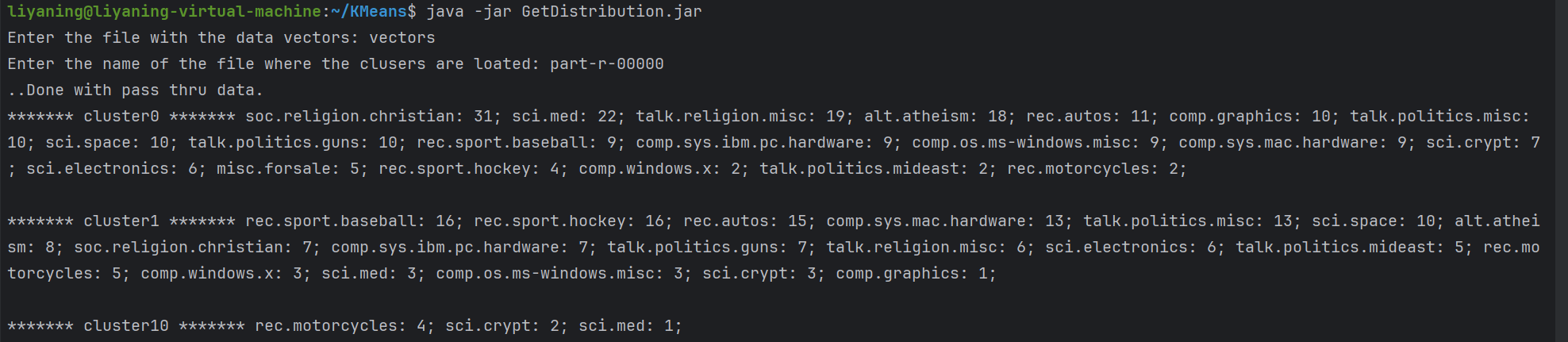
使用命令java -jar GetDistribution.jar运行检查结果的jar文件。按照如下信息输入:
Enter the file with the data vectors: vectors
Enter the name of the file where the clusers are loated: part-r-00000
你应当能看到以下结果信息:
# Done!
大功告成!你做的很棒,你已经完成了云计算的第二次实验。在本次实验中,你安装并配置了Hadoop以及HDFS等相关配套设施,你使用Hadoop完成了wordcount和KMeans两个小实验,现在你可以完善一下你的实验报告准备提交,同时休息一下看看窗外的风景,晚餐加个鸡腿奖励一下自己。
- 01
- openclaw使用以来若干问题的拒绝方案03-10
- 02
- 安装sharetex后更换为完整镜像02-21